腾讯文档-武大:web前端
##第一周:前端基础及ES6讲解
前端三剑客
-
html:结构 。
块:div,h1,p,header等;行内元素:span,input,img,a
Html5: 提供了更加语义化的标签。
<meta> 描述html元数据,定义页面作者,浏览器解析。
-
css:外观
- css选择器
- 盒模型
- Flex,栅格布局
- 定位:relative,absolute,fixed(相对浏览器窗口的固定位置)
-
js:行为
- 函数
- 对象
- 闭包
- 原型链
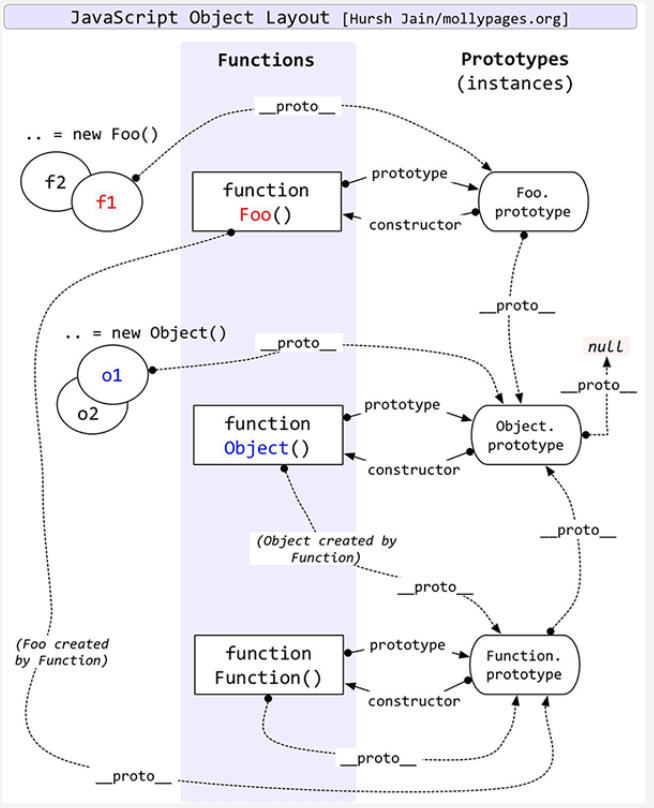
- DOM
第二周
TypeScript
TypeScript = Typed JavaScript at Any Scale
TypeScript是什么
TypeScript 是 JavaScript 的严格超集,类型是TS最核心的特性,TS适用于任何规模的项目
- JavaScript是解释类型语言,没有编译阶段,运行时进行类型检查
- TS运行前需要先编译为JS,编译阶段会进行类型检查,所以TS是静态类型
- TS是弱类型语言,和JS都允许隐式转换
符合最新ECMAScript标准
优点
-
TS类型定义和编译器的引入,能够让我们避免掉JS的很多错误
-
在大型系统中,能够知道某个变量的类型定义是很有价值的。
React优势
- 组件化
- 数据驱动:修改数据,组件重新渲染
- 虚拟DOM:在需要的时候会渲染成真实DOM,结合Diff算法来提升性能,支持跨平台渲染
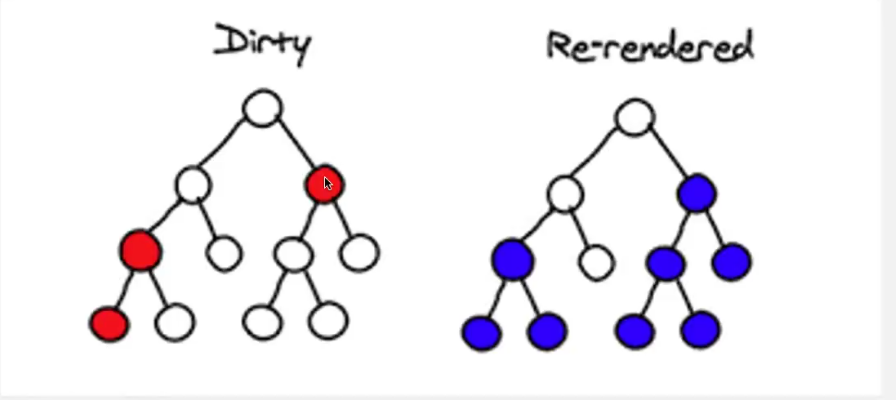
父节点,子节点也重新更新。叶子结点更新就只更新叶子结点。
- 跨端渲染
NPM
Package.json:描述项目信息,依赖,版本,脚本等
npm init:初始化项目,生成package.json文件
Npm install:自动安装package.json下面等所有模块
npm publish:发布自己的库到npmjs
第三周
构建工具
构建工具:将前端源代码自动转成js,html,css等
比如:ES6 -> ES5
JSX ->运行时js组件

例子:
html和js分离时,
原来: html引用同域JS。
现在CDN加载(跨域)
构建工具的发展
早期:seajs, requirejs(node.js)
2011-2014: gulp(基于配置,流式), grunt, webpack, browserify
2015: rollup(解决webpack的一些问题,支持shaking)
2017: parcel
近两年:vite, snowpack(只用打包改动的代码)
webpack社区活跃
为什么webpack,不是vite
从使用广度,构建能力,使用场景,工具生态,webpack是最佳方案
vite生态可能没有webpack成熟,有一些坑
webpack
一切皆模块,通过loader转换文件,plugin注入钩子实现
各版本:

基本使用
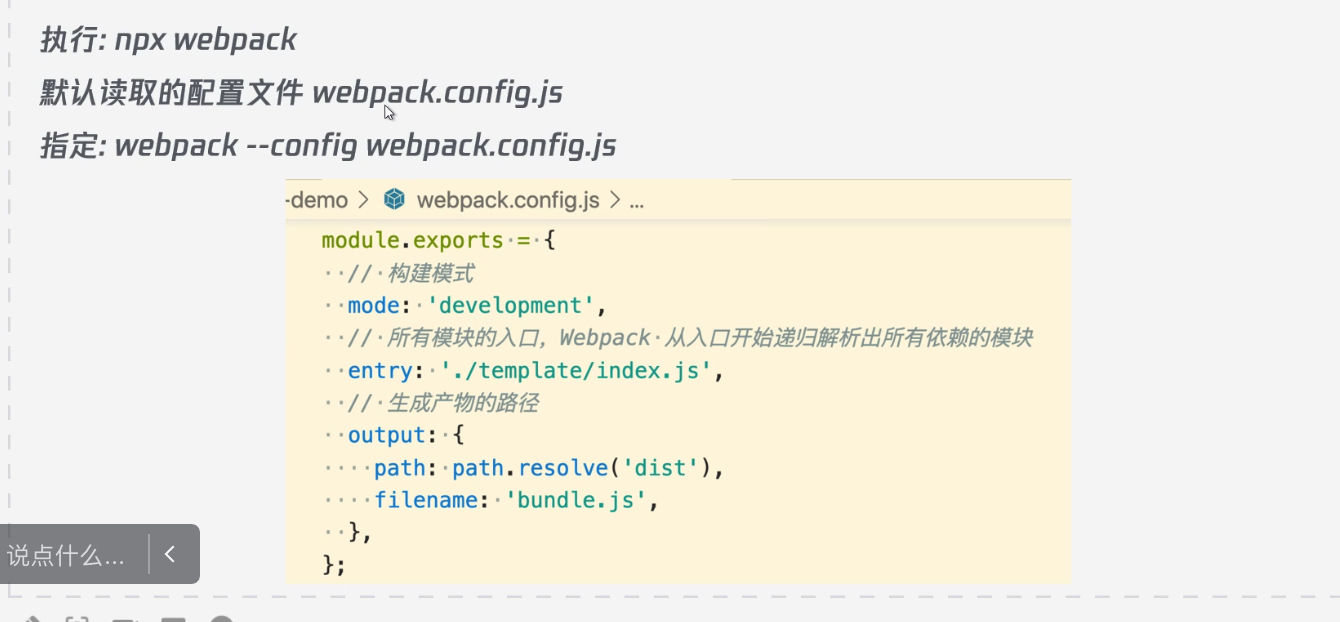
Mode:
- Development: 不压缩,调试
- Production:压缩,开启优化选项
Output :
-
Path: 输出文件路径
-
publicPath:配置发布到线上资源的URL前缀
Plugin:
- 比如HtmlWebpackPlugin
Loader:webpack核心
把一切文件看作模块,对不同类型的文件,进行不同处理
laoder来扩展对不同文件的处理能力。loader是一个处理函数
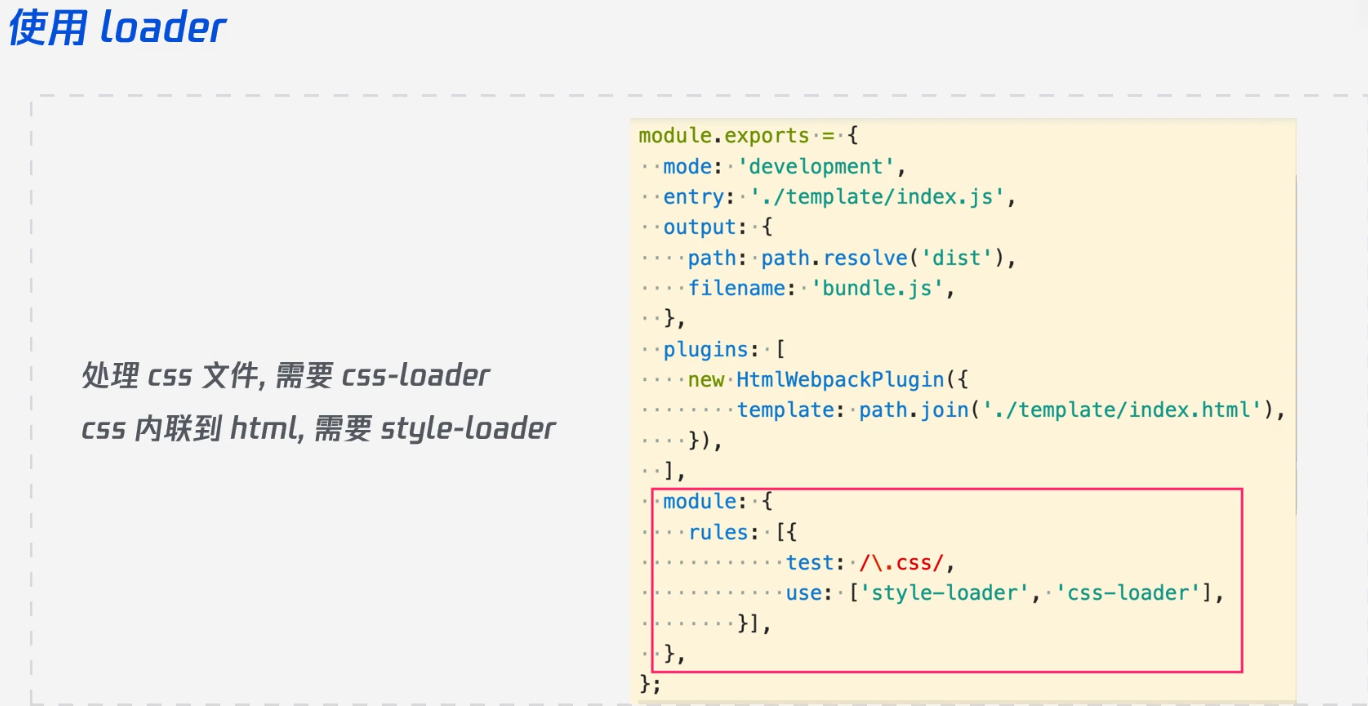
读取匹配到的文件源码,进行转换,生成代码
devServer
提供http服务而不是本地文件预览
监听文件变化并自动刷新网页

hot:true
热更新:在网页不刷新情况下,将老的代码替换为新代码
进阶使用
ES6配置

图片配置
构建中使用url-loader处理图片资源
使用limit来限制图片大小
页面代码加载优化方式
1、按需加载
大型网站打开时加载全部代码,会导致页面加载缓慢,交互卡顿
使用异步加载的方式,按需加载和使用

关键是await语句
2、提取公共代码
打包时会把公共部分打包在一个文件中
Http和https
usl中的fragment,方便定位页面元素
http:超文本传输协议
http报文分为请求报文和响应报文
http请求方法:
- GET:从指定资源中请求数据。没有副作用,不会更新资源
- POST:用于将数据发送到服务器以创建或更新资源(一般是非幂等)
- PUT:和post一样,一般是幂等等
- delete
GET和POST区别

http状态码
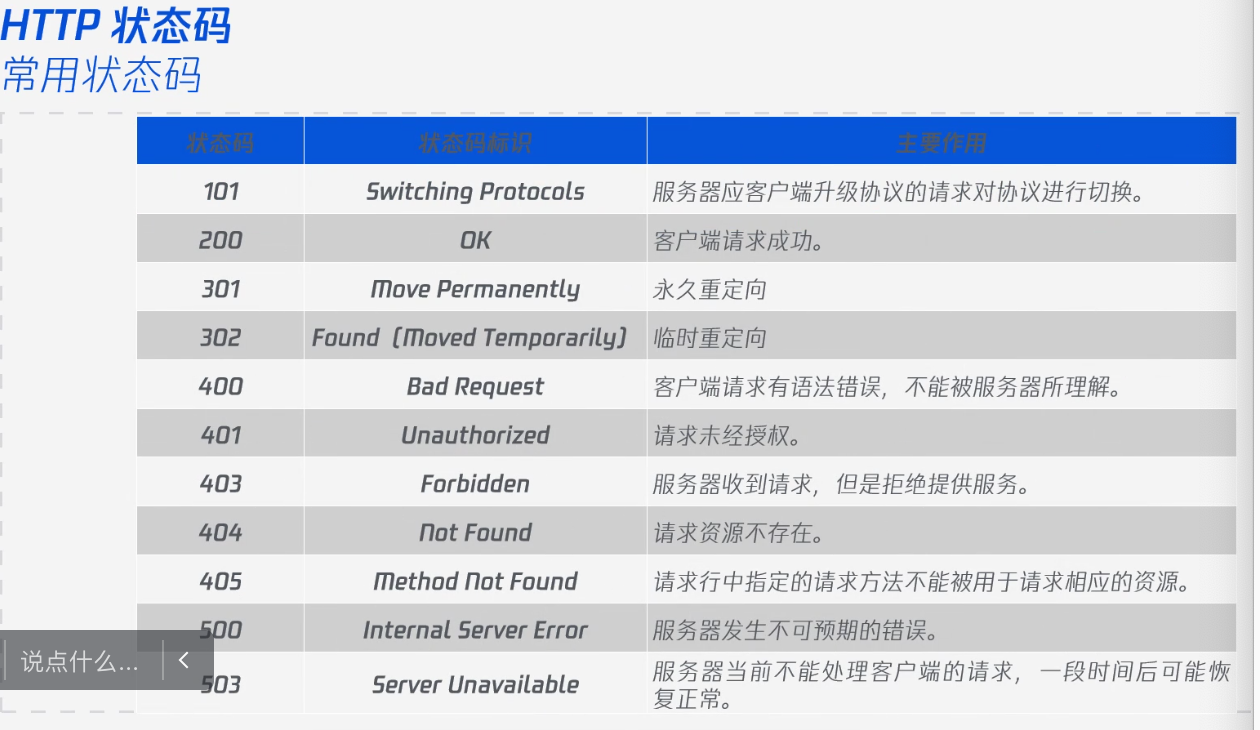
思考:为什么http是无连接无状态?
前提:基于tcp
减轻服务端压力,不用保持链接状态

Http1.1的优化

Https

思考:服务器怎么向客户端推送消息
短轮询
指在特定的的时间间隔(如每1秒),由浏览器对服务器发出HTTP request,然后由服务器返回最新的数据给客户端的浏览器。
请求中有很多是无用的,浪费带宽和服务器资源;响应的结果没有顺序(因为是异步请求,当发送的请求没有返回结果的时候,后面的请求又被发送。而此时如果后面的请求比前面的请 求要先返回结果,那么当前面的请求返回结果数据时已经是过时无效的数据了)
长轮询
客户端向服务器发送Ajax请求,服务器接到请求后hold住连接,直到有新消息才返回响应信息并关闭连接,客户端处理完响应信息后再向服务器发送新的请求。
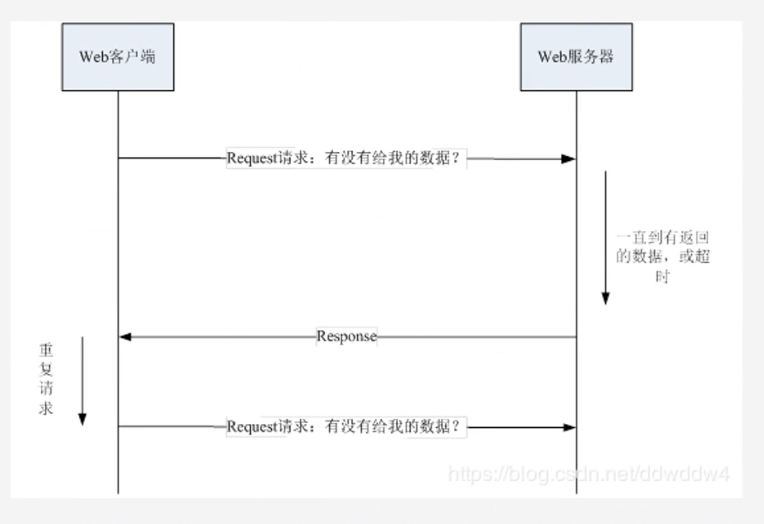
缺点:服务器端一直保持链接,占用资源
解决方法:SSE, server-sent event
web端即时通讯技术
websocket:html5新技术
腾讯文档:你写一个数据在表格中,其他人马上能看到变化。使用websocket,服务器端广播
浏览器跨域问题
同源策略
同源:只有 同协议,同域名,同端口,才能叫同源
为什么同源?
cookie和session 安全问题
cookie相当于一个工牌或者学生卡,别人拿到了也能刷
访问了一个网站之后又访问其他网站,其他网站如果读取第一个网站的cookie怎么办: 同源
如何规避同源策略
cookie:
- 两个网站一级域名相同,第二级域名不同,可以设置document.domain共享cookie
iframe同源策略限制
同源策略下,网页不同,不能拿到另一个网页的dom
解决:h5引入全新API:跨文档通信API: cross-document message
AJAX方法
-
服务器代理跨域:由服务器端来拿另一个网站的策略
-
JSONP:添加script标签
-
终极解决方案:CROS, w3c标准,是跨源ajax请求的根本解决方法
- 相比于jsonp只能发get,cros支持任何类型请求
- 浏览器自动完成,不需要用户参与
缓存
浏览器缓存
浏览器获取的http资源,保存到本地磁盘
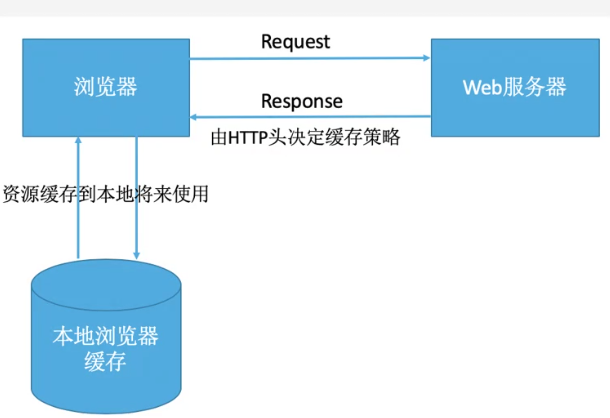
为什么缓存:
减轻服务器端压力,页面加载速度更快
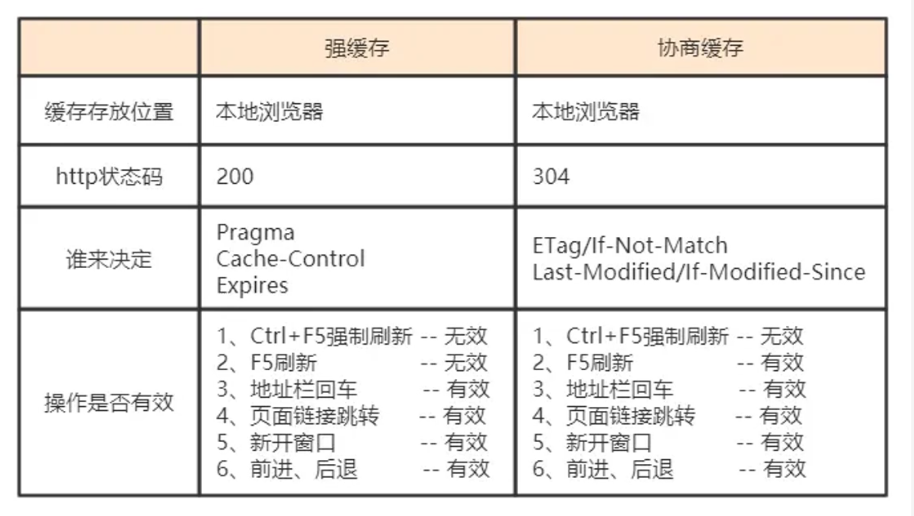
缓存分类
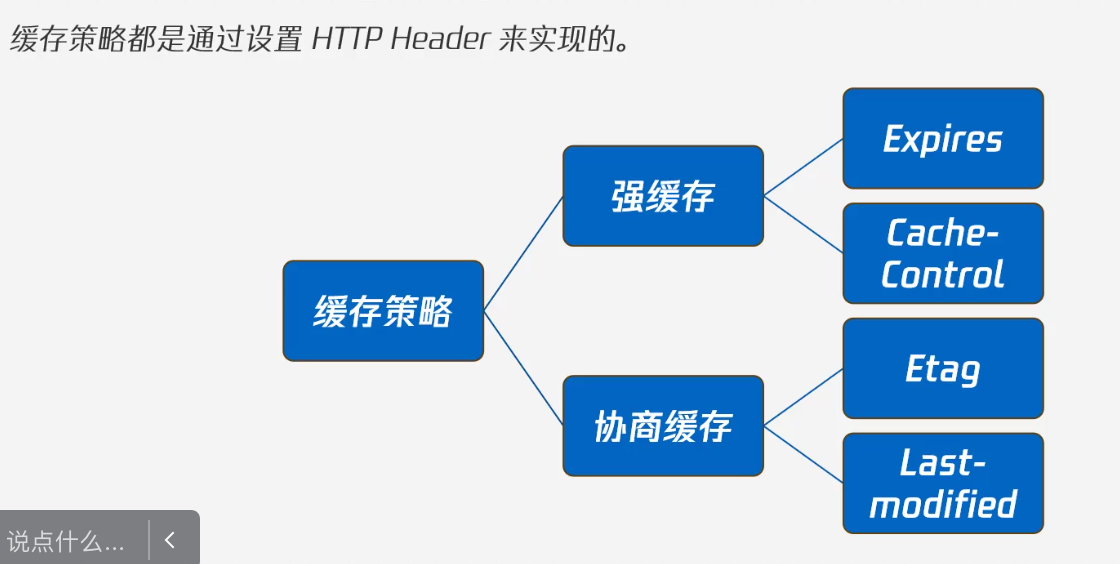
强缓存
- Expires: http1.0产物,过期了,存在是为了兼容性
- Cache- Control: http1.1产物
协商缓存
-
Etag和If-none-match
-
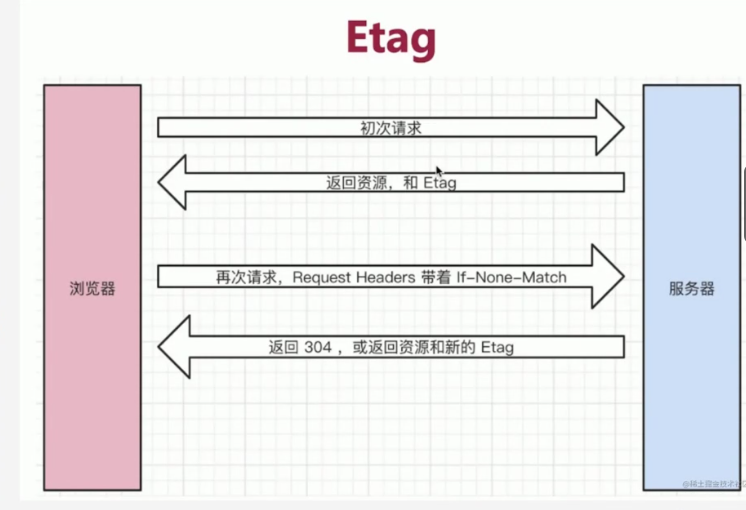
-
last-modify和if-modify-since
Last-modify:只记录时间
强缓存和协商缓存区别
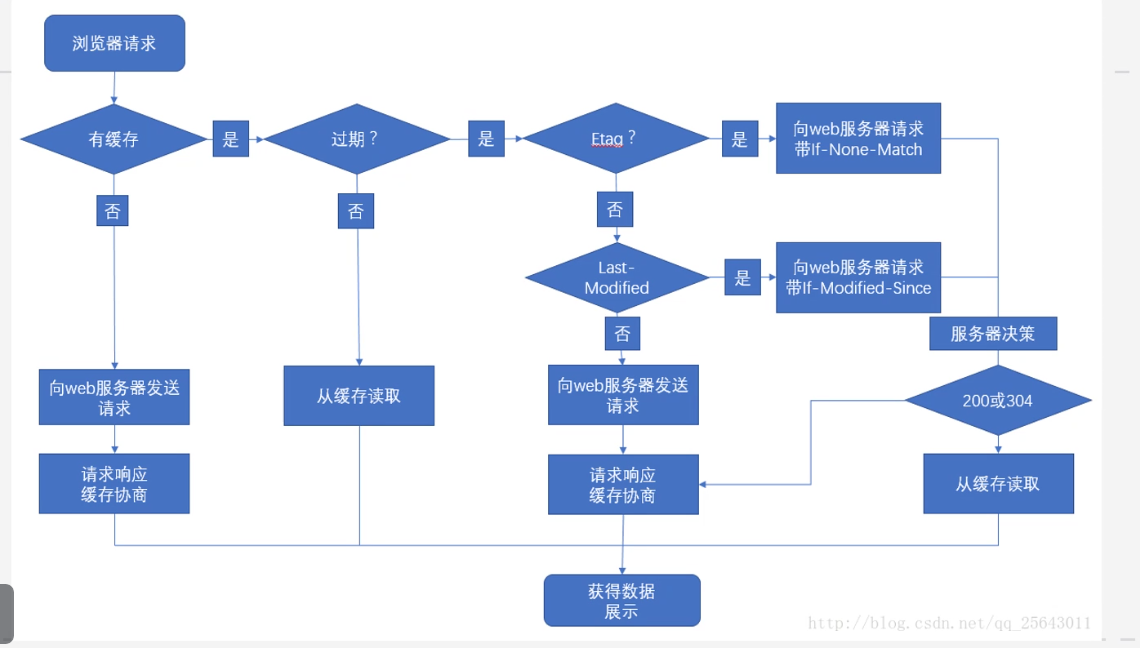
区别在于需不需要向服务器请求
缓存过程
网络攻击
-
XSS
Cross Site Script跨站脚本,为了和css区分叫xss
- 存储型XSS:黑客将恶意代码发向服务器,服务器端存储。用户访问界面拿到的是有黑客的恶意代码的页面
- 反射型XSS
- 基于DOM型的XSS
预防XSS:对输入做验证
-
CSRF
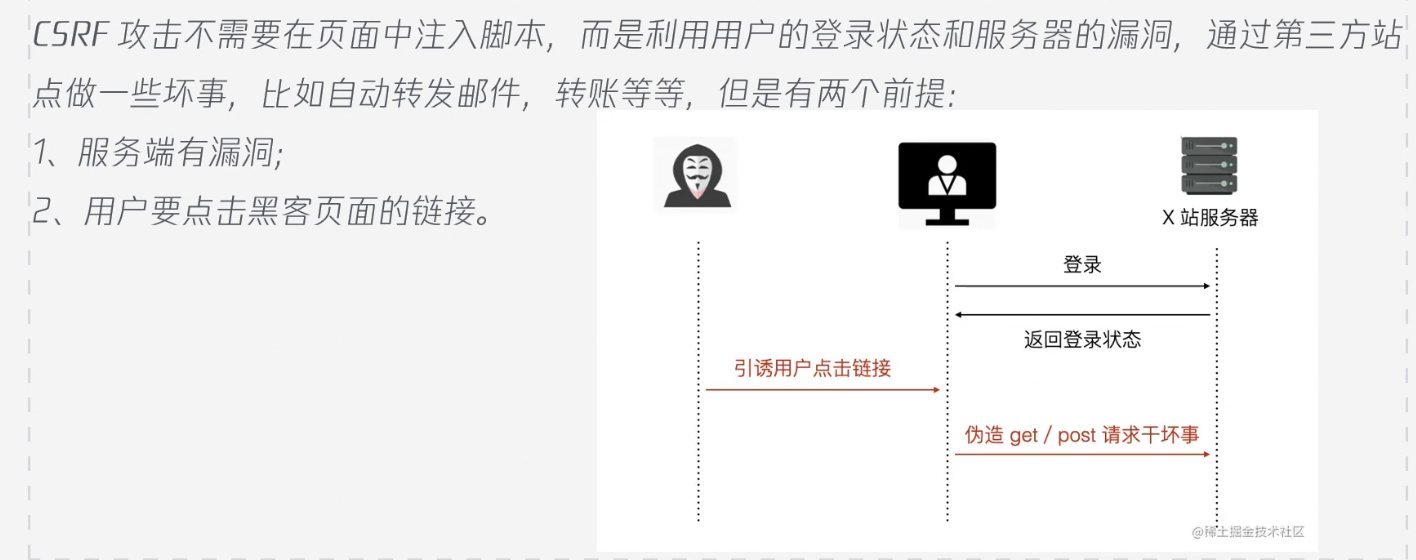

重点是token验证
第四周
前端工程化和编码规范
- 目录结构
- 文件命名规范
- 代码规范:eslint,prettier
为什么有了eslint还要用prettier?
eslint发现代码错误
prettier是代码格式化器,不关心代码逻辑
husky:
解决git commit有时候忘记eslint或prettier
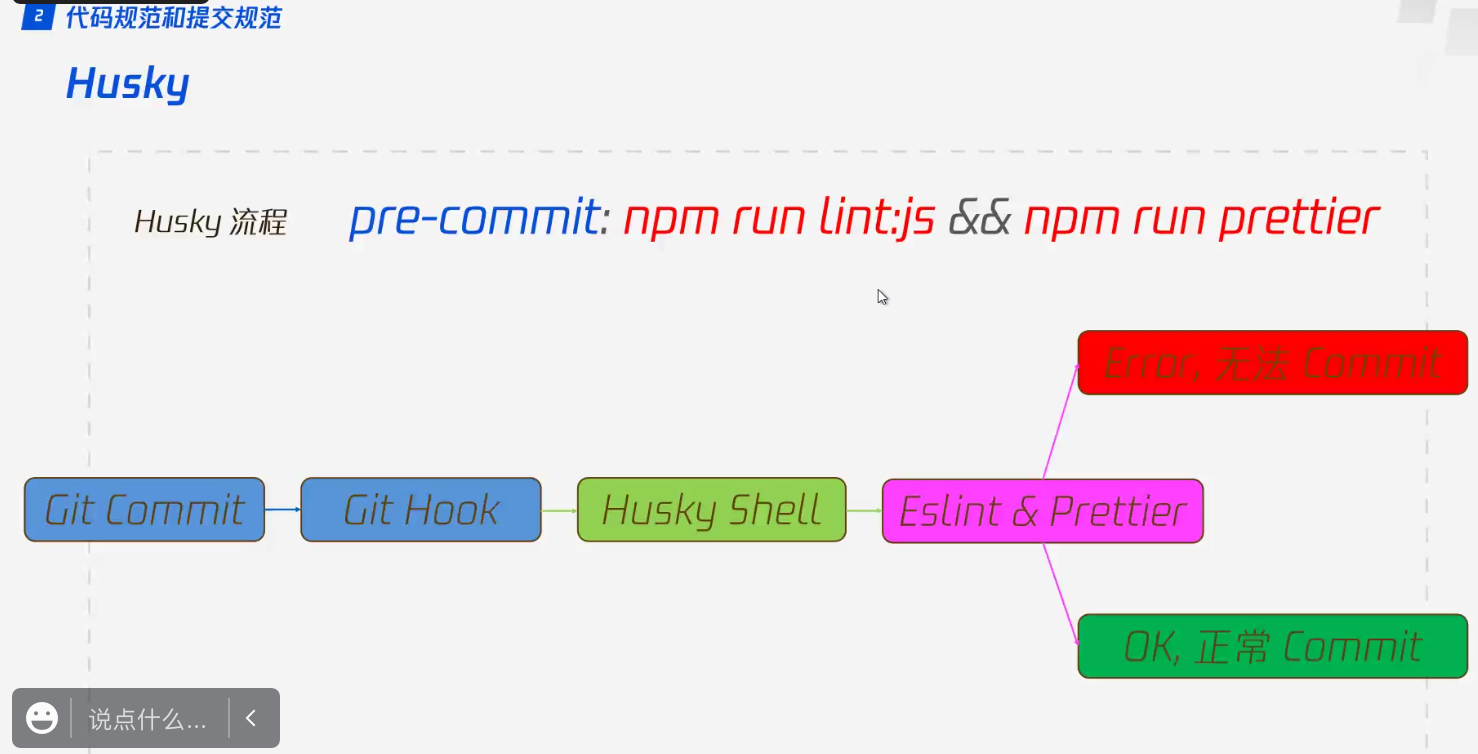
Lint staged : 只检查当前改动的eslint,防止把别人的错误检查出来,却要自己改
- 提交规范
commitlint
commitizen:可以自己选改动的类型
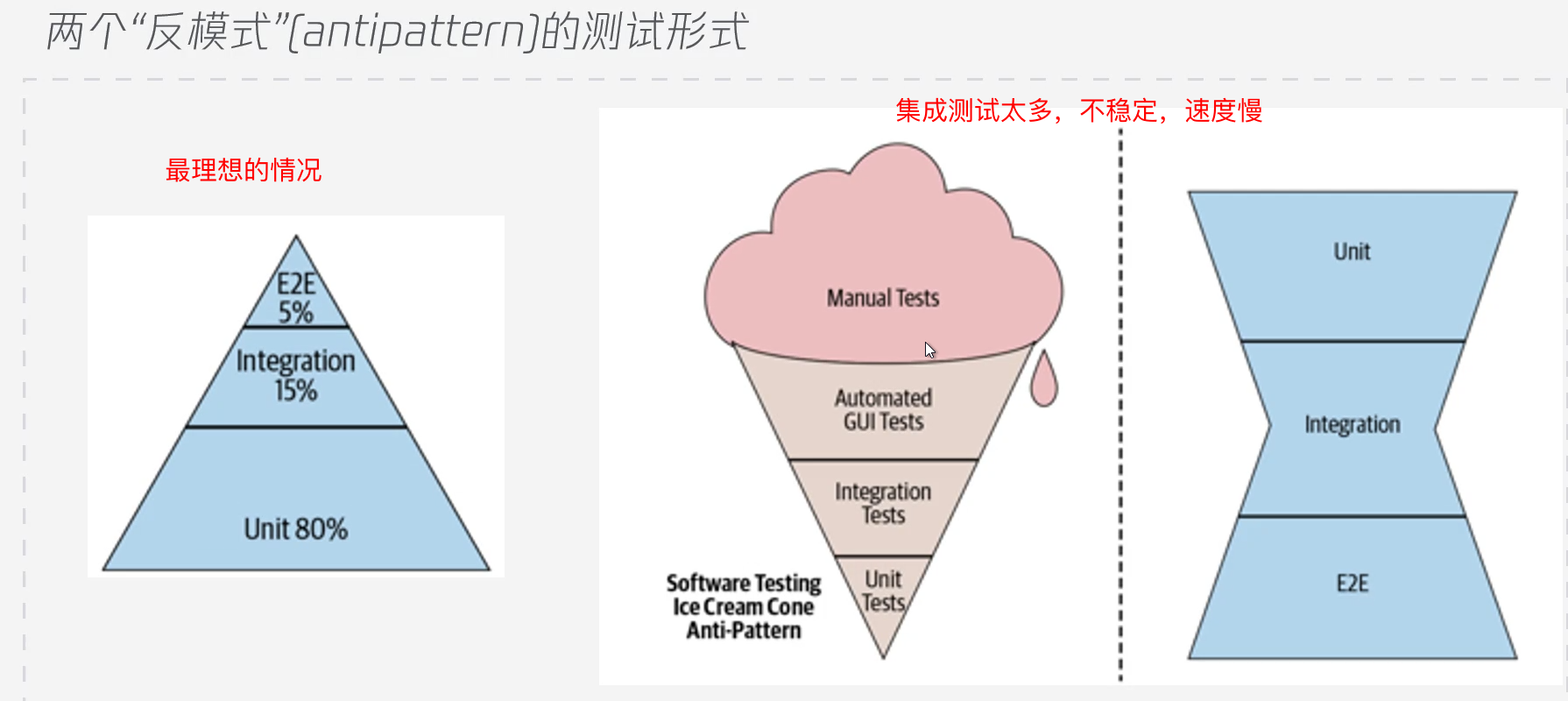
Jest单测
为什么单测:
- 更少的问题排查时间
- 代码在他的生命周期里实际上不会一成不变
- 经过测试的代码提交后出现问题的可能性更小
- 让整个团队受益
- 更准确的文档
- 维护文档非常痛苦,且容易过时
- 想知道一段代码的调用方式,可以直接看测试
- 更方便的代码审核
设计原则
所有设计模式的实现都遵循一条原则,即“找出程序变化的情况”
单例模式
保证一个类中只有一个实例
在js中全局变量常常被当成单例模式,var a = {} ;
但是同意造成命名空间污染
我们需要尽量减少全局变量的使用
使用闭包封装私有变量:
var user = (function(){
var userInfo = new UserInfo();
return{
getUserInfo: function(){
return userInfo;
}
}
})
怎么避免每次都new一个UserInfo?
使用惰性单例:
var user = (function(){
var useInfo = null;
return{
if(!useInfo){
useInfo = new UseInfo();
}
getUseInfo: function(){
return useInfo;
}
}
})
发布-订阅模式
定义对象间一对多的依赖关系,当一个对象的状态发生变化时,所有依赖于它的对象都将得到通知

加一个中介:

问题在于:模块之间的联系被隐藏到背后
享元模式
装饰者模式
允许向一个现有的对象添加新的功能,同时又不改变其结构
思考一个游戏升级问题,A飞机升级时增加了技能,如何设计?
最简单的方法:继承,问题:数量多,强耦合
装饰器模式。
工厂模式
提供一种创建对象的方式
设计原则
所有的设计原则的目的都是让程序低耦合,高复用,高内聚,易扩展,易维护
单一职责原则
一个对象(方法)只做一件事
并不是所有的职责都应该一一分离
srp原则的优点是降低了单个类或对象的复杂度,缺点是增加了代码编写的复杂度
开闭原则
软件实体(类,模块,函数)等应该是可以扩展的,但是不可修改
- 对软件测试友好,不会破环原有的测试程序
- 改动代码是一个危险的行为,经常不知不觉引发了其他bug
通过封装变化的方式,把系统中稳定不变的部分和容易变化的部分隔离开来
如:发布订阅模式,新的订阅者出现后,发布者不需要修改任何代码
依赖倒置原则
面向接口编程而不是面向实现编程