DOM(2021-1-31)
DOM 简介
Document Object Model ,是 W3C 推荐的处理可扩展标记语言 HTML 或 XML 的标准编程 接口
用来改变网页的内容,样式等
页面 = 文档,用 document 表示
元素 = 标签: 用 element 表示
节点:所有内容(属性,标签,文本,注释)都是节点,用 node 表示
DOM 把以上内容都看作对象
获取元素
ID : document.getElementById(id),返回匹配 id 的元素对象,id 是字符串
console.dir()打印元素对象,查看其中的属性和方法
标签名:document.getElementByTagName(),返回伪数组
element.getElementByTagName()
H5:通过类名,document.getElementByClassName()
document.querySelector('.box') 类 。返回指定选择器的第一个元素对象
document.querySelector('#nav') id
document.body之类的也行
事件
三部分:事件源,事件类型,事件处理程序
var btn = document.getElementById('btn'); //事件源:按钮
btn.oncliick = function(){ //事件类型:点击
alert(‘按钮被点击’); //事件处理程序
}
element.InnerText 来改元素内容,不识别 HTML 标签,非标准,去掉空格和换行
element.InnerHTML能识别 html 标签,用的更多
2021-2-2
密码框显示密码常用这样:
var flag = 0;
Btn.onclick = function () {
if (flag == 0) {
pwd.type = "text";
flag = 0;
} else {
pwd.type = "password";
flag = 1;
}
};
js 修改 css
属性采用驼峰命名
element.style.backgroundColor = ' ‘,改的是行内样式
关闭淘宝二维码案例
用display:none
var btn = document.querySelector(".close-btn");
var box = document.querySelector(".box");
btn.onclick = function () {
box.style.display = "none";
};
循环精灵图案例
for 循环修改 background-position
var lis = document.querySelectorAll("li");
for (var i = 0; i < lis.length; i++) {
var index = i * 44;
lis[i].style.backgroundPisition = "0 -" + index + "px";
}
焦点事件
element.onfocus获得焦点
element.onblur失去焦点
element.className 直接改类名,适合样式改的 比较多的时候
操作元素
//获取
element.attribute //获取内置属性
element.getAttribute('id') //可以获取自定义属性,最常用
//h5新增
div.dataset.index
//修改
element.attribute = ' '
element.setAttribute('id',nav) //可以修改自定义属性
改className就直接'class',不用className
节点操作
1,通过 DOM 操作,逻辑性不强,操作复杂
2,利用节点操作,更简单
parentNode //离节点最近的父级节点,找不到就返回为null
childNodes //子节点,包含文本节点,元素节点等,标准
//只想获得元素节点,需要专门处理(用nodeType来判断,所以一般不用)
children //获取所有的子元素节点,常用
firstElementChild //第一个子元素节点
lastElementChild //最后,这两个都有兼容问题
//实际开发写法:
children[0]
children[length-1]
垃圾回收
参考资料:https://zh.javascript.info/garbage-collection
JavaScript 中主要的内存管理概念是 可达性。
简而言之,“可达”值是那些以某种方式可访问或可用的值。它们一定是存储在内存中的。
-
这里列出固有的可达值的基本集合,这些值明显不能被释放。
比方说:
- 当前函数的局部变量和参数。
- 嵌套调用时,当前调用链上所有函数的变量与参数。
- 全局变量。
- (还有一些内部的)
这些值被称作 根(roots)。
-
如果一个值可以通过引用或引用链从根访问任何其他值,则认为该值是可达的。
比方说,如果全局变量中有一个对象,并且该对象有一个属性引用了另一个对象,则 该 对象被认为是可达的。而且它引用的内容也是可达的。下面是详细的例子。
在 JavaScript 引擎中有一个被称作 垃圾回收器 的东西在后台执行。它监控着所有对象的状态,并删除掉那些已经不可达的。
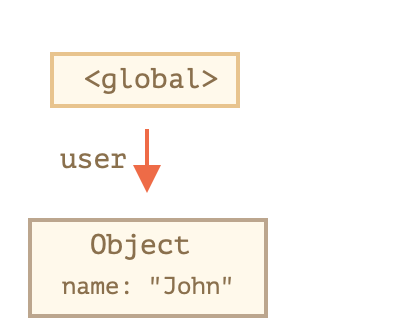
Object是可达的,若: user = null;
则:
变为不可达了,垃圾回收器会进行回收,释放内存。
JS引擎做的优化:
- 分代收集(Generational collection)—— 对象被分成两组:“新的”和“旧的”。许多对象出现,完成它们的工作并很快死去,它们可以很快被清理。那些长期存活的对象会变得“老旧”,而且被检查的频次也会减少。
- 增量收集(Incremental collection)—— 如果有许多对象,并且我们试图一次遍历并标记整个对象集,则可能需要一些时间,并在执行过程中带来明显的延迟。所以引擎试图将垃圾收集工作分成几部分来做。然后将这几部分会逐一进行处理。这需要它们之间有额外的标记来追踪变化,但是这样会有许多微小的延迟而不是一个大的延迟。
- 闲时收集(Idle-time collection)—— 垃圾收集器只会在 CPU 空闲时尝试运行,以减少可能对代码执行的影响。
原始类型的方法
参考资料:https://zh.javascript.info/primitives-methods
原始类型和对象之间的关键区别。
一个原始值:
- 是原始类型中的一种值。
- 在 JavaScript 中有 7 种原始类型:
string,number,bigint,boolean,symbol,null和undefined。
一个对象:
- 能够存储多个值作为属性。
- 可以使用大括号
{}创建对象,例如:{name: "John", age: 30}。JavaScript 中还有其他种类的对象,例如函数就是对象。
JavaScript 创建者面临的悖论:
- 人们可能想对诸如字符串或数字之类的原始类型执行很多操作。最好将它们作为方法来访问。
- 原始类型必须尽可能的简单轻量
为了使原始类型的方法起作用,js创建了提供额外功能的特殊“对象包装器”,使用后即被销毁。
(可以联系JAVA的包装类来思考?)
例如:
例如,字符串方法 str.toUpperCase() 返回一个大写化处理的字符串。
用法演示如下:
let str = "Hello";
alert( str.toUpperCase() ); // HELLO
发生了如下过程:
1,为了访问toUpperCase()方法,js创建了一个对象,对象里面存放了hello以及toUpperCase()方法
2,程序调用toUpperCase()方法
3,调用完毕,js销毁该对象,只留下原始值str
这样可以保证原始类型依然是轻量的
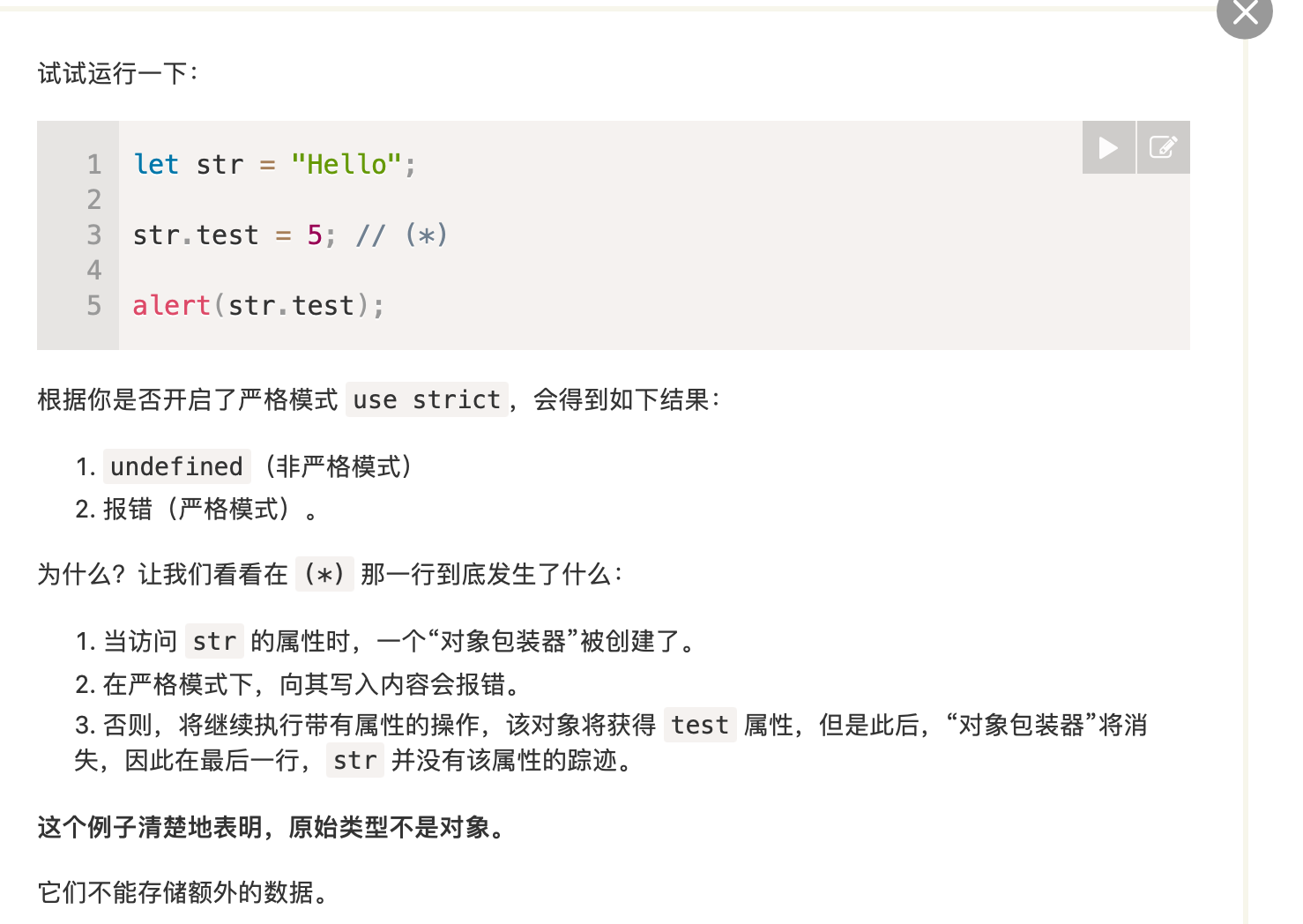
这个例子很好地说明了上面的一点,并且表明原始类型无法添加额外的属性。其实要使用额外的属性,直接自己创建一个对象就好了。
常用方法
数字类型
toString();
Math.floor();//向下舍入
Math.ceil();//向上舍入
Math.round();//四舍五入
toFixed(n);//舍入小数点n位 ,return string
parseInt 和 parseFloat:
它们可以从字符串中“读取”数字,直到无法读取为止。如果发生 error,则返回收集到的数字。函数 parseInt 返回一个整数,而 parseFloat 返回一个浮点数
Math.random() //0-1随机数
Math.max(a,b,c,....)
Math.min();
Math.pow(n,power);
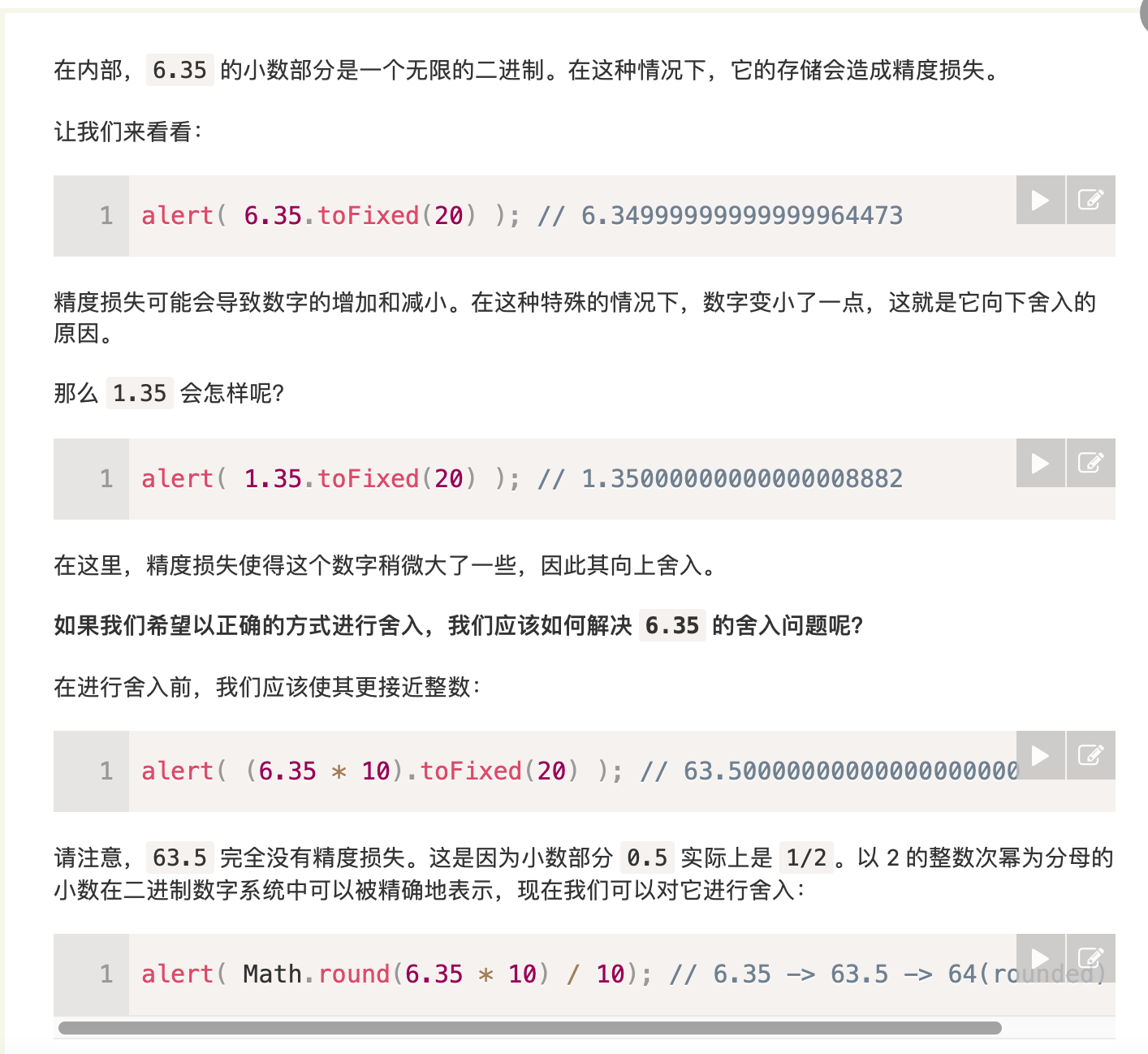
注意这种问题:
字符串
str.lenght //是一个属性
str.charAt(pos)
遍历字符串:
for (let char of "Hello") {
alert(char); // H,e,l,l,o(char 变为 "H",然后是 "e",然后是 "l" 等)
}
字符串不可改
toLowerCase()和toUpperCase()
str.indexOf(substr, pos) // 从pos开始找子串str,如果没有找到,则返回 -1,否则返回匹配成功的位置。
str.lastIndexOf(substr, pos) //从末尾开始找
str.includes(substr, pos) //根据 str 中是否包含 substr 来返回 true/false
str.startsWith(substr)/str.endsWith(substr) // 判断是否以substr开始/结束
str.slice(start [, end]) //返回字符串从 start 到(但不包括)end 的部分。start/end 也有可能是负值。它们的意思是起始位置从字符串结尾计算
str.substring(start [, end]) //返回字符串在 start 和 end 之间 的部分。
str.codePointAt(pos) //返回pos位置的字符代码
String.fromCodePoint(code) //通过数字 code 创建字符